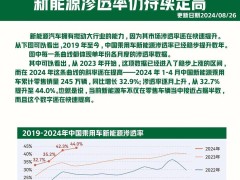
在近日舉辦的全球云計算領域年度盛會中,亞馬遜云計算服務(AWS)正式推出新一代自研AI訓練芯片Trainium3,并同步發布基于該芯片的Trainium3 UltraServer服務器。這款硬件組合通過架構革新與工藝升級,為生成式AI模型的訓練與推理提供全新解決方案,標志著AWS在垂直整合計算資源領域邁出關鍵一步。
據技術披露,Trainium3芯片采用臺積電3納米制程工藝,單芯片集成144GB HBM3E內存,內存帶寬達4.9TB/s,在FP8精度下可提供2.52 PFLOPS算力。其性能較前代產品實現四倍躍升,能效比與內存帶寬同樣獲得近四倍優化。通過新一代Neuron網絡架構,芯片間通信延遲被壓縮至10微秒以內,配合NeuronSwitch-v1實現的雙倍內部帶寬,有效解決了分布式訓練中的通信瓶頸問題。
UltraServer服務器將硬件集成度推向新高度。單臺設備最多可容納144顆Trainium3芯片,形成20.7TB HBM3E內存池與706TB/s總帶寬的超級計算單元,FP8算力峰值達362 PFLOPS。實測數據顯示,該系統運行GPT-OSS開源模型時,單芯片吞吐量提升300%,推理響應速度加快4倍,顯著降低企業應對流量峰值的硬件投入成本。目前Amazon Bedrock服務已率先在生產環境部署該硬件。
在應用場景方面,這套硬件組合展現出顯著優勢。對于千億參數級模型訓練,其可將周期從數月壓縮至數周;面對智能對話、視頻生成等高并發推理需求,能以微秒級延遲服務百萬級用戶。多家合作伙伴已驗證其成本效益:Decart公司借助Trainium架構將實時視頻生成速度提升4倍,同時將單位推理成本削減50%;生物科技企業metagenomi則通過硬件優化將基因序列分析效率提升3.5倍。
為滿足超大規模計算需求,AWS同步推出EC2 UltraCluster 3.0架構。該集群通過高速互聯技術可連接數千臺UltraServer,形成百萬級芯片計算矩陣,較上一代規模擴大十倍。這種擴展能力使得在萬億token數據集上訓練多模態模型成為可能,同時可為千萬級用戶提供實時推理服務,為自動駕駛、氣候模擬等前沿領域提供基礎設施支撐。
市場布局方面,AWS正面臨雙重挑戰。一方面需應對谷歌TPU在AI芯片市場的持續滲透,特別是Anthropic等戰略客戶近期宣布將采購百萬級谷歌芯片;另一方面要鞏固與現有合作伙伴的關系——該生成式AI公司仍計劃年底前部署超百萬顆Trainium2芯片,其中近半數將運行于Project Rainier超級計算機。為保持競爭力,AWS同步披露下一代Trainium4研發進展,新芯片在FP4精度下性能將提升六倍,FP8性能提升三倍,并首次引入NVIDIA NVLink Fusion技術實現異構計算協同。
這項技術整合計劃引發行業關注。通過將Trainium4與Graviton處理器、EFA網絡適配器部署在統一MGX機架,AWS旨在構建兼具成本優勢與性能彈性的AI基礎設施。這種模塊化設計既支持純CPU計算場景,也可靈活擴展GPU與Trainium混合架構,為不同規模的AI工作負載提供定制化解決方案。隨著軟硬件協同優化的持續推進,AI訓練與推理的成本門檻有望進一步降低。