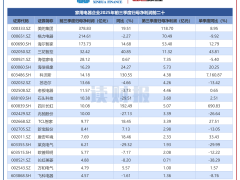
阿里巴巴與新加坡攜手打造的東南亞多語言大模型Qwen-SEA-LION-v4,近日在“東南亞語言模型全面評估基準”(SEA-HELM)開源模型榜單(參數量2000億以下)中拔得頭籌。這一成果標志著中新兩國在人工智能領域的深度合作取得突破性進展。
東南亞地區語言生態極為復雜,擁有超過1200種語言,日常交流中多語言混用現象普遍。然而全球主流AI模型多以英語為核心構建,難以滿足本地化需求,導致該地區長期面臨“AI鴻溝”困境。此次推出的Qwen-SEA-LION-v4模型,正是為破解這一難題而生。
該模型的技術根基源于阿里巴巴自主研發的“通義千問”開源框架。研發團隊在預訓練階段即納入119種語言數據,為理解東南亞小語種構建了堅實基礎。通過在后訓練階段顯著提升跨語言任務比重,模型有效強化了對多語言混合輸入的處理能力,更貼近真實應用場景需求。
為推動技術普惠,AISingapore官網與HuggingFace開源社區已同步開放模型下載服務。這一舉措不僅為東南亞開發者提供關鍵技術支撐,也為全球AI社區貢獻了處理復雜語言環境的重要解決方案。目前該模型已展現強大潛力,在醫療、教育、政務等多個領域具備廣泛應用前景。